Table of Contents
Regular expressions in AntConc
author: @sabinebartsch
[Tutorial Status: under construction [2021-11-29]]
Simple regular expressions
Regular expressions are supported in AntConc in two flavours. Simple regex support exists for AntConc queries out of the box and require no further settings or boxes being ticked. This can be seen from the fact that the query box allows the user not only word queries, but enables queries using so-called wildcards (think of them as generic place holders for a sequence of characters or symbols) such as
*ed that finds all words ending in -ed such as past tense forms of regular verbs.
This enables the user to formulate queries over sets of words with joint character sequences etc.
This simple regex functionality also allows the user to use wildcards for individual letters. In order to search for the following words with a single query:
bag or big or bug
enter the following regex: b?g
The simple AntConc Search Term function also allows concatenation of query items:
big|great|large finds the any instance of any of the listed items
take|took|taken|taking finds all forms of the irregular verb take
Full regex implementation
AntConc also features a fuller implementation of regular expressions. It can be activated by checking the RegEx box above the right hand side of the query box (see the read arrow pointing at the check box in the image below).
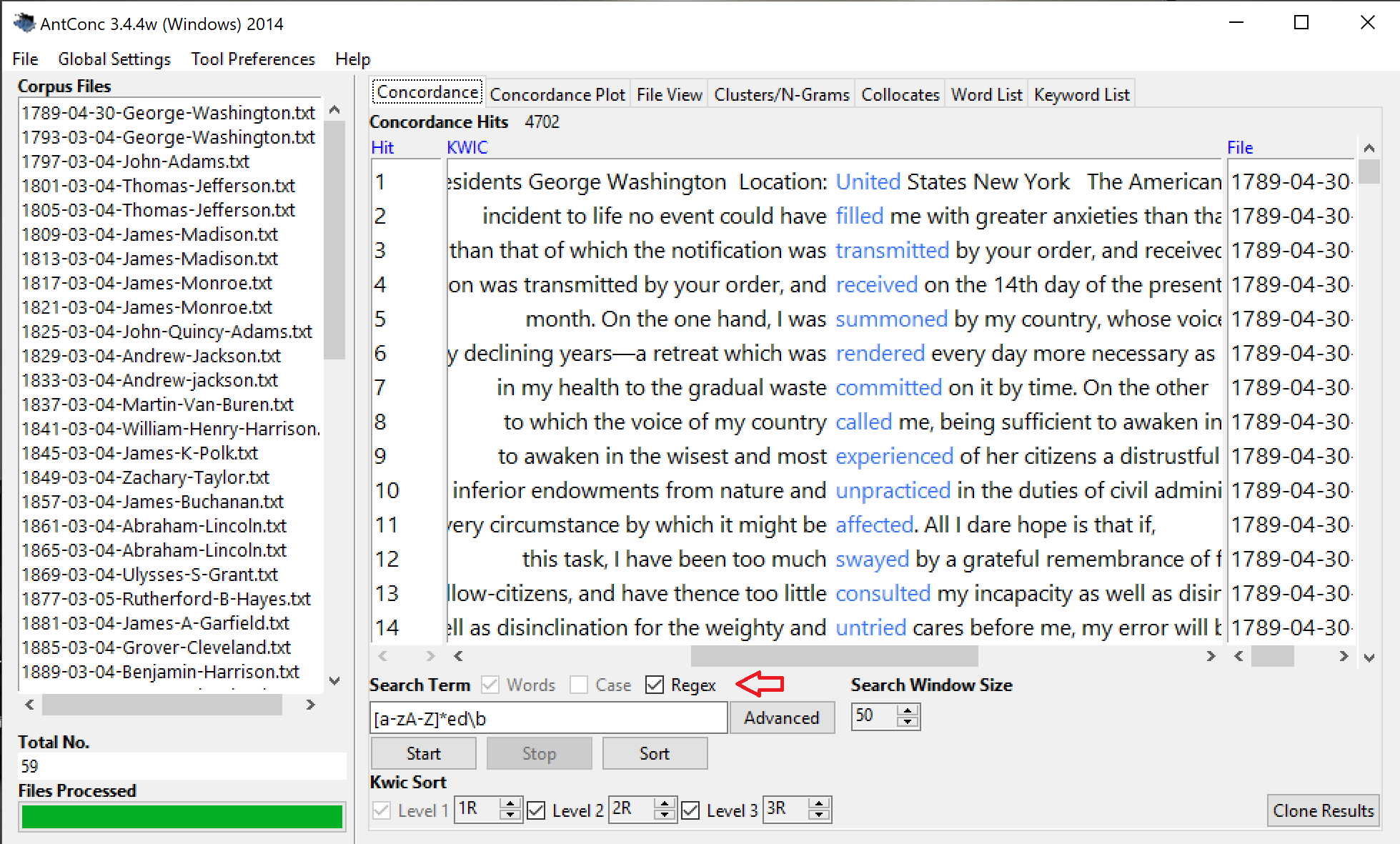
Check this box to change to the more extensive, non-simplified implementation to use the full power of regular expressions in your searches.
The example query entered in the box reads:
[a-zA-Z]*ed\b
[a-zA-Z] serves as a representation of all the lower case or upper case alphabetic character;
the fact that this expression is surrounded by square brackets signifies that this stands for a so-called range of characters.
If followed by the so-called asterisk which in this regex implementation stands for 'any number of whatever stands directly in front of the asterisk' the expression will match any number of the characters in the brackets, so effectively, the beginning of the word. This is then followed by the character sequence ed (the regular past tense suffix in English verbs).
This is then followed by:
\b
which is the regex shortcut for the word boundary. This ensures that ed is only matched at the end of the word.
The next sections offer descriptions of regex based queries over unannotated plain text files followed by a section on queries over part of speech tagged files.
Regular expressions for queries on unannotated plain text
Regular expressions are a powerful tool for text queries and there is often more than one way of achieving the same goal. In particular, regular expression syntax often implements so-called metacharacters, i.e. shortcuts for frequently used character sequences and other recurring phenomena. An example is the above mentioned metacharacter | which stands for or, other such shortcuts are for example \b for the word boundary or \w for word characters (see table below).
[a-zA-Z] for the range of alphabetic characters likewise has a quasi-equivalent in
\w
So instead of writing
[a-zA-Z]*ed\b
you could also write
\w*ed\b
Note that \w will find a bit more than [a-zA-Z]. It typically defines the range of so-called word characters as [A-Za-z0-9_]; in corpus linguistics you may find including numbers in words useful if you are carrying out research over domain-specific texts that contain numbers in words, e.g. in chemistry texts.
Regular expressions for queries over annotated text
AntConc supports queries over annotated data, esp. part of speech tagged data. If you have in-text part of speech tags, you can not only search over the tokens, but also formulate search patterns incorporating part of speech tags.
Corpus example: 2009-01-20-Barack-Obama - Inauguration Speech / Stanford PoS Tagger - model: english-left3words-distsim.tagger
I_PRP thank_VBP President_NNP Bush_NNP for_IN his_PRP$ service_NN to_TO our_PRP$ Nation_NNP ,_, as_RB well_RB as_IN the_DT generosity_NN and_CC cooperation_NN he_PRP has_VBZ shown_VBN throughout_IN this_DT transition_NN ._.
Forty-four_CD Americans_NNPS have_VBP now_RB taken_VBN the_DT Presidential_JJ oath_NN ._.
The_DT words_NNS have_VBP been_VBN spoken_VBN during_IN rising_VBG tides_NNS of_IN prosperity_NN and_CC the_DT still_RB waters_NNS of_IN peace_NN ._.
Yet_RB every_DT so_RB often_RB ,_, the_DT oath_NN is_VBZ taken_VBN amidst_IN gathering_VBG clouds_NNS and_CC raging_VBG storms_NNS ._.
At_IN these_DT moments_NNS ,_, America_NNP has_VBZ carried_VBN on_IN not_RB simply_RB because_IN of_IN the_DT skill_NN or_CC vision_NN of_IN those_DT in_IN high_JJ office_NN ,_, but_CC because_IN we_PRP the_DT people_NNS have_VBP remained_VBN faithful_JJ to_TO the_DT ideals_NNS of_IN our_PRP$ forebears_NNS and_CC true_JJ to_TO our_PRP$ founding_VBG documents_NNS ._.
A corpus of this format token_tag can be easily queried by means of the simple as well as full regular expression syntax. An example shall illustrate first of all a simple syntax (uncheck the regex box) example and the resulting output:
query: people
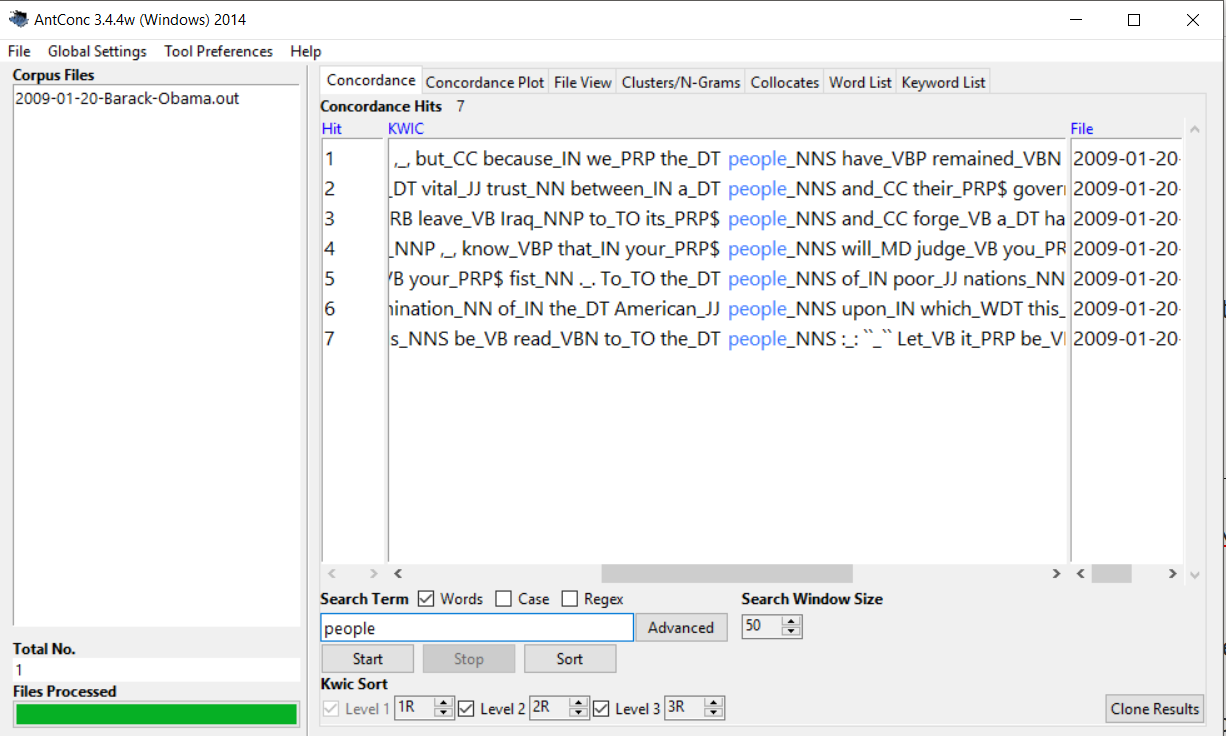
This query finds all instances of the token people as you can see in the screenshot above.
And because the text is part of speech tagged, you can likewise query to find words tagged with a particular part of speech tag:
fellow_JJ finds instances of the word fellow tagged as an adjective by means of the Penn Treebank tag-set.
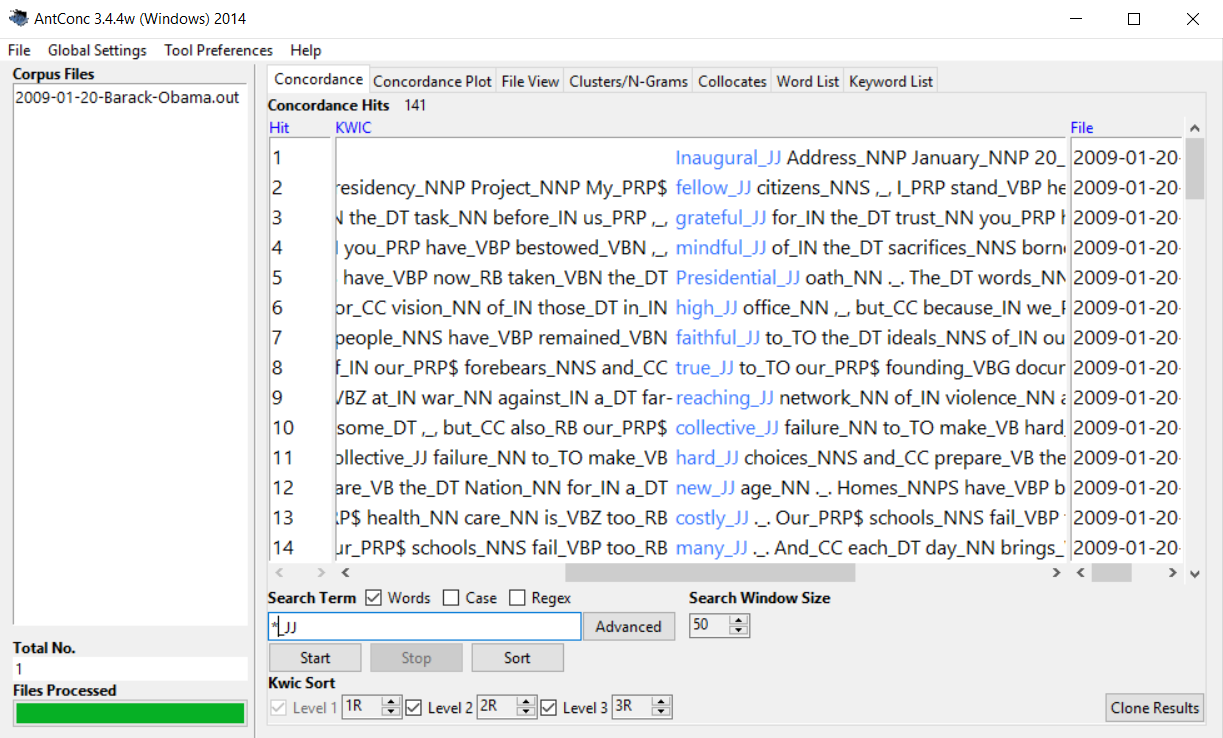
If you are interested in seeing all adjectives, you can do that by means of this query - again in the simple reg ex version:
*_JJ
What you might not like so much is that the resulting concordance not only shows the tokens, but also their part of speech tags. So, in other words, the annotation is visible which makes it hard to follow the actual text. In order to prevent this, you can get AntConc to hide the tags, but still allow you to access them in your search patterns. In order to do that, you have to change the default settings in AntConc. In the top horizontal menu, select Global settings and in the vertical Category list select Tags. The following window will open:
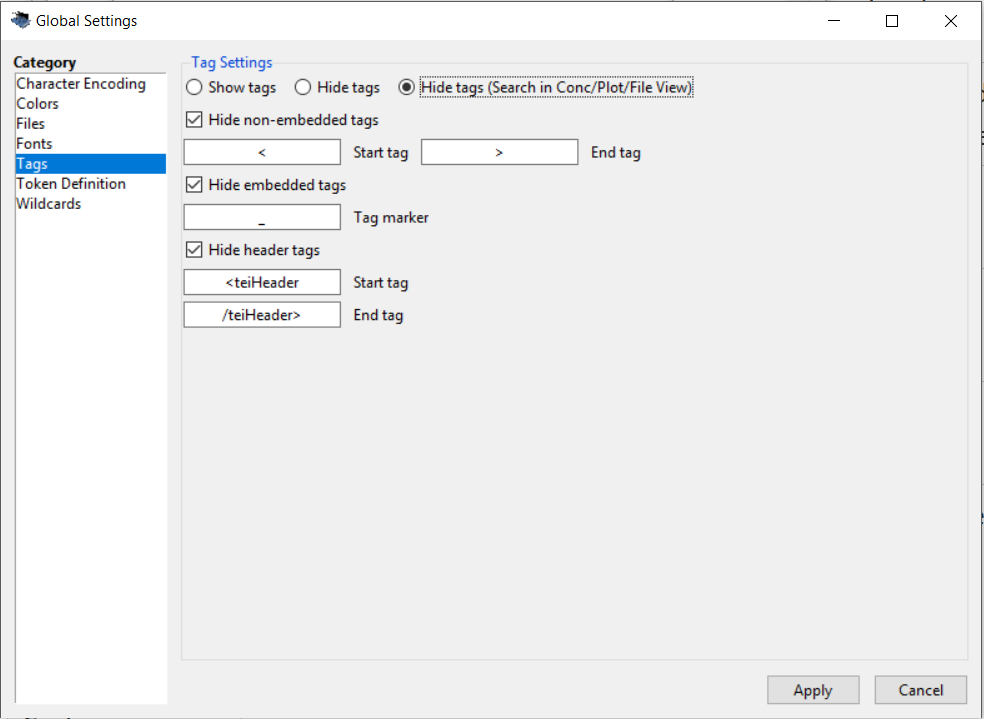
From the top of the window under Tag settings select the radio button Hide tags (Search in Conc/Plot/File view).
If the delimiter between token and tag is an underscore (_), you are all set as a little further below the Tag marker is already set to the underscore. If your part of speech tagger produces backslashes as tag delimiters, you can change this here from the underscore to the backslash. For my example, we are done here and only have to press Apply at the bottom for the changes to take effect.
Once you are done here, you can now run the following queries:
fellow_JJ matches instances of the token fellow as an adjective
*_JJ matches all adjectives in the corpus
*_JJ citizens matches all adjectives that occur directly in front of the token citizens
Note that in the resulting concordance you see only the tokens, but you can still search for the tags.
The setting Hide tags (Search in Conc/Plot/File view) is not only of relevance for the data display in the concordance tab, but especially for the Word list function tab. If you do not adjust this setting, AntConc wrongly counts every part of speech tag as a token, because the underscore is read as a word delimiter. So in order to generate correct word lists from part of speech tagged corpora, this setting is crucial in order to get accurate results.
AntConc: Simple regex examples
| regular expression | example result | explanation |
*ed | walked, talked etc. | asterisk followed by ed finds all tokens ending in ed |
under* | understand, understood, underpass etc. | word beginning followed by any sequence word characters |
b?g | bag, big, bog, bug | finds all tokens beginning with b and ending in g with exactly one character that can vary in the middle |
a|an | a, an | finds either the first word or the second; can be extended to more words |
AntConc: Full regex examples (check regex box)
| regular expression | example result | explanation |
[a-zA-Z]* | matches range of all lower case and upper case characters, e.g. abc, UK, Sydney | range of characters in square brackets, the asterisk after the closing bracket means at least one of these |
\w | finds full words | \w matches the so-called word-characters, i.e. alphanumeric characters including all upper case and lower case alphabetical characters plus digits, and in most implementations including the underscore _; note that [a-zA-Z] and \w cannot be used entirely interchangeably. If you are trying to match the correct form of a URL, it might be quite detrimental to use \w, because it allows alphanumeric characters that include diacritics such as à, é, č, Å that are not permissible in URLs |
\b | word boundary | you can use \btag-set\b to ensure that your query only matches full words |
 Except where otherwise noted, content on this wiki is licensed under the following license: CC Attribution-Share Alike 4.0 International
Except where otherwise noted, content on this wiki is licensed under the following license: CC Attribution-Share Alike 4.0 International